Paper Download Address
Abstract
1)Question
生成caption时帧中的无关信息及生成的caption(word)对后续信息生成帮助不大(冗余造成干扰),致使模型无法生成有效信息。
2)Method/Model
CAM(encoder部分)
①Visual Attention:在图像中定位与caption相关物的位置
a. region level :CNN卷积层对每一帧均提取m个(固定)2D(空间)特征,并对其安全求和,即可得到一帧的特征信息。
b. frame level: CNN卷积层利用region level提取出的2D特征,对取出的几帧提取3D(空间+时间)特征。
②Text Attention:在已生成的caption中定位主体物内容
③Balancing gate:平衡visual&text的内容
RNN(decoder部分)
该模型中选用了LSTM作为解码器,以充分利用历史信息。
3)Answer
已成功在MSVD、Charades、MSR-VTT、MRII-MD上取得不错的成绩。
Introduction
1)Model Contribution
①两层的visual attention:可以同时定位到关键帧(frame)&关键区域(region),同时信息结构&帧间平滑度不会被破坏。
②phrase-level text attention mechanism:短语级别的文本注意机制,优化了word-level时非视觉性词汇无法提供所需的前置信息的情况,即phrase-level可以定位到与当前生成词最近的previous caption.
③balancing gate:平衡门,用于生成nonvisual words(a、the、is等),具体方法是在最后单词期望分布的计算公式中在Visual特征前加入控制参数λ,当λ==0时相当于不受visual特征的控制,有利于通过文本特征生成非视觉性词汇,提高语法正确性。
2)Article Structure
SEC II:related work:a.Machine Translation b.Image Caption c.Video Caption
SEC III: CAM-RNN
SEC IV:experiments
Conclusion
在MSVD、Charades、MSR-VTT、MRII-MD等数据集上的得分都较传统方法有了略微的提升(那提升着实微妙)(详见后面Experiments部分~)
该模型可以迁移至image caption、video question-answer等应用中。
Model
Probability Distribution
t时间步候选单词的概率分布计算公式: \(p_t=softmax(tanh(W_p[\gamma_tV_t,E_t,h_t]+b_p))\) 其中,V_t为视觉特征,E_t为文本特征,h_t为t时刻隐藏岑状态,γ_t为平衡门参数,通过激活函数tanh函数将值域激活至(0,1),再通过softmax得到最终的概率分布。
训练使用最大似然估计法: \(\theta^*=arg\,\max_{\theta} \sum_{t=1}^T logP_r(\Psi_t|\Psi_{t-1},V_t,E_t;\theta)\)
Visual Feature Extraction with Attention
Region-Level Attention
-Goal:extract frame feature(定位每帧上的突出的部分,即为该帧的特征)
设在第每帧有固定的m个注意区域,没个区域的特征为r_{i,j},则对第i帧的frame feature的按权求和计算如下:
\[\xi_i=\sum_{j=1}^m\alpha_{i,j}r_{i,j}\]其中α_{i,j}为第i帧第j个区域的权重,有:
\[\alpha_{i,j}=\frac{exp(q_{i,j})}{\sum_{j=1}^mexp(q_{i,j})}\\ q_{i,j}=w_rtanh(W_rr_{i,j}+U_r\alpha_{i-1,j}+b_r)\]q_{i,j}的计算同时与区域特征和上一帧该区域的权重有关,使attention保持连续性。
Frame-Level Attention
-Goal:encode visual feature from the most correlated frames.
视每n帧为一个时间步,则对第t步,视觉特征(3D)的按权求和计算如下:
\[V_t=\sum_{i=1}^n\beta_{t,i}\xi_i\]其中β_{t,i}为第t时间步第i帧的权重,有:
\[\beta_{t,i}=\frac{exp(l_{t,i})}{\sum_{i=1}^nexp(l_{t,i})}\\ l_{t,i}=w_ftanh(W_f\xi_i+U_fh_{t-1}+b_f)\]l_{t,i}同时与帧特征和上一时间步的隐藏层状态有关。
Text Feature Extraction with Attention
-Goal:calculate text feature at each time step
体现phrase-level
对于previously generated words的编码有:
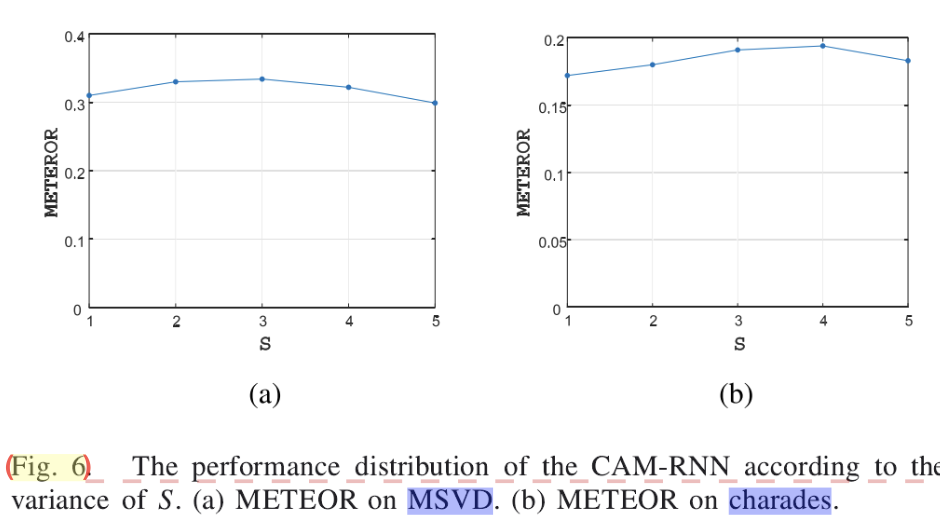
\[\rho_{t,s}=tanh(W_Se_{t-s:t-1})\ \ \ \ \ s\in 1,2,3\]由上述Experiments中的Results on Baseline得,s=3时短语级别的文本注意效果最佳,故此处分别对s=1、2、3,即分别对前1、2、3步生成单词组成的短语进行编码,此后可得到文本特征E_t:
\[\eta_{t,s}=\frac{exp(z_{t,s})}{\sum_{s=1}^3exp(z_{s,t})}\\ z_{t,s}=w_Ztanh(W_z\rho_{t,s}+U_zh_{t-1}+b_z)\]LSTM
此处仅列参数衔接公式,详见笔者另一篇博客《【ML Basic】LSTM实现机制及其常用变式》,该论文使用的即为传统LSTM。
\[i_t=\sigma(W_ix_t+U_ih_{t-1}+b_i)\\ f_t=\sigma(W_hx_t+U_hh_{t-1}+b_h)\\ o_t=\sigma(W_ox_t+U_oh_t+b_o)\\ g_t=\sigma(W_gx_t+U_gh_{t-1}+b_g)\\ c_t=f_tc_{t-1}+i_tg_t\\ h_t=o_t\Phi(c_t)\]Balancing gate
在前面单词概率分布的式子中也提到γ_t参数的意义,其计算如下:
\[\gamma_t=sigmoid(W_\gamma*h_t)\]即根据当前隐藏层的状态利用sigmoid函数进行激活。结合最终的单词概率分布公式可得,当γ较小时则视觉信息几乎不发挥作用,这样就有利于非视觉词汇的生成,从而提高语法正确性。
Experiments
1) Results of Baselines
-Premise:由VggNet统一提供特征编码内容,控制变量,由此对三个结构(视觉注意、文本主义、平衡们)分别进行检验是否有效。
-Results:
①Visual Attention Module: 【对照组:None-RNN、Frame-RNN、Visual-RNN】
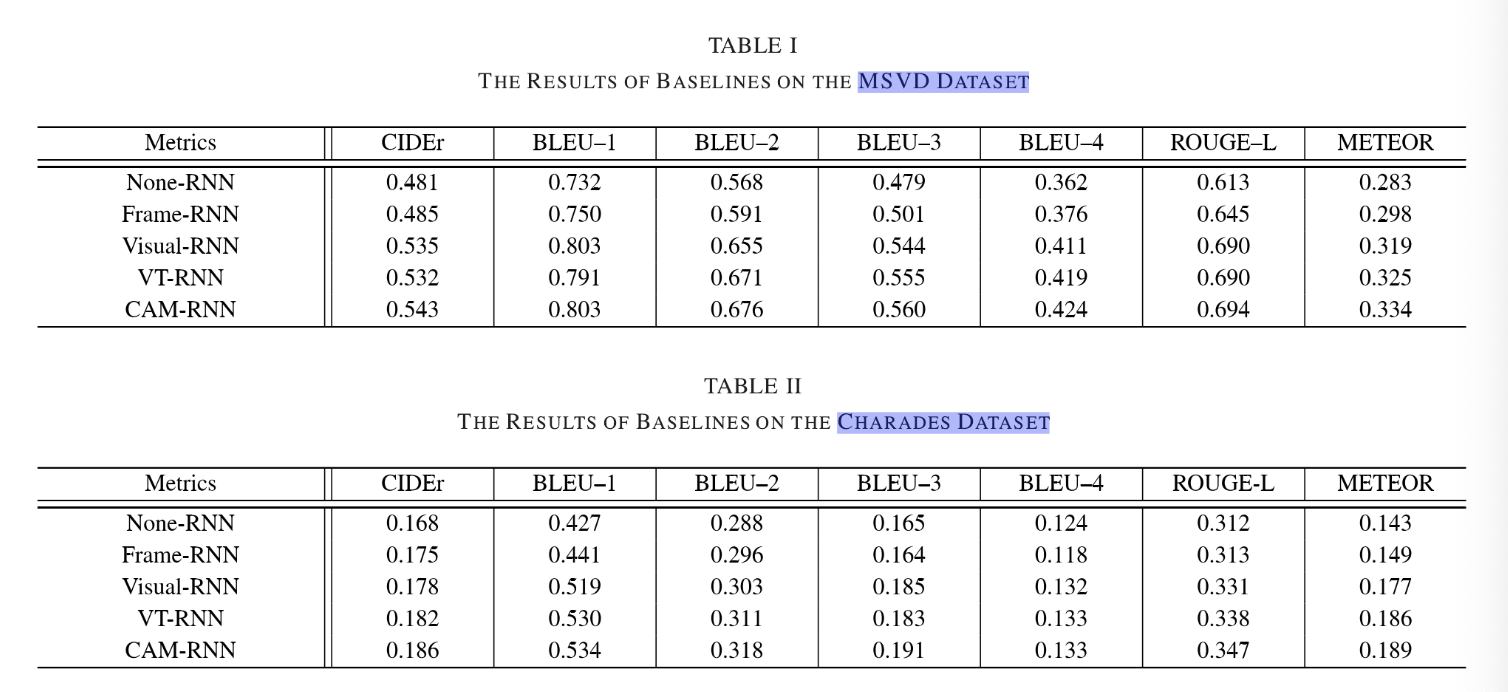
②Text Attention Module: 【对照组:Visual-RNN、VT-RNN】由描述结果可看出CAM-RNN生成的描述更少有语法错误:

另外,对于短语级别的注意力机制,模型通过在MSVD、charades上的训练,得到S=3(注意力范围,即可用的prewords)为最佳:
③Balancing gate:CAM-RNN与VT-RNN的唯一区别即在于平衡门的有无,从TableI、TableII中也可看出平衡门的有效性。

2)Results on MSVD
①各种模型在CIDer、BLEU、ROUGE-L、METEOR数据及上的测试结果:
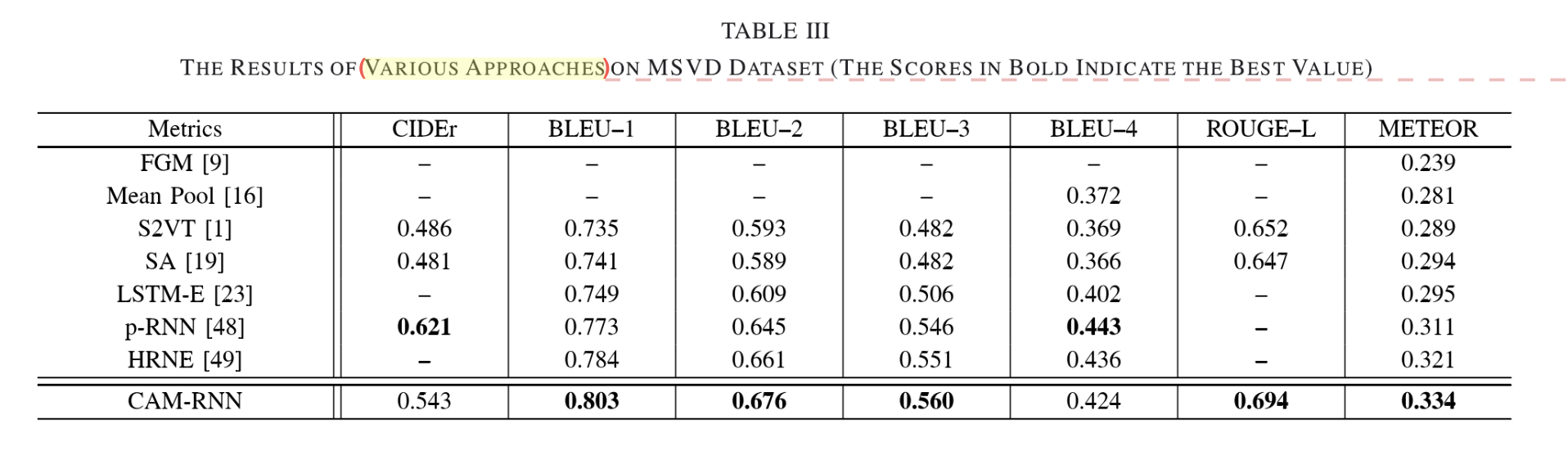
CAM-RNN在CIDEr上表现不好的原因在于CIDEr弱化了对非视觉性词汇的考量,无法体现出CAM-RNN的优势。
知识补充:
【FGM】无RNN,传统方法中的state-of-the-art
【Mean Pool、LSTM-E】早frame feature上加入mean pool
【S2VT】一层LSTM以encode
【S2VT-LM】S2VT+language model(获取语言信息)
【HRNE】双层LSTM以encode
【SA】frame attention(simple attention机制)
【p-RNN】region attention引入
②另外,将各种模型、encoder(三种最常用的:VggNet、GoogLeNet、C3D)进行组合检验进行测试:
补充:VggNet、GoogLeNet进行特征提取、C3D获取动态信息,其对权重参数p的影响相同 (搞大创的时候想如果用这个的话其实可以调整一下VggNet/GoogLeNet和C3D的占比权重以达到不同的效果,溜了溜了)
\[p=\frac {p_{vggnet}+p_{c3d}}{2}\ or\ p=\frac{p_{googlenet}+p_{c3d}}{2}\]
3)Results on Charades
【对照组:S2VT、SA、MAAM】在Charades上的表现:
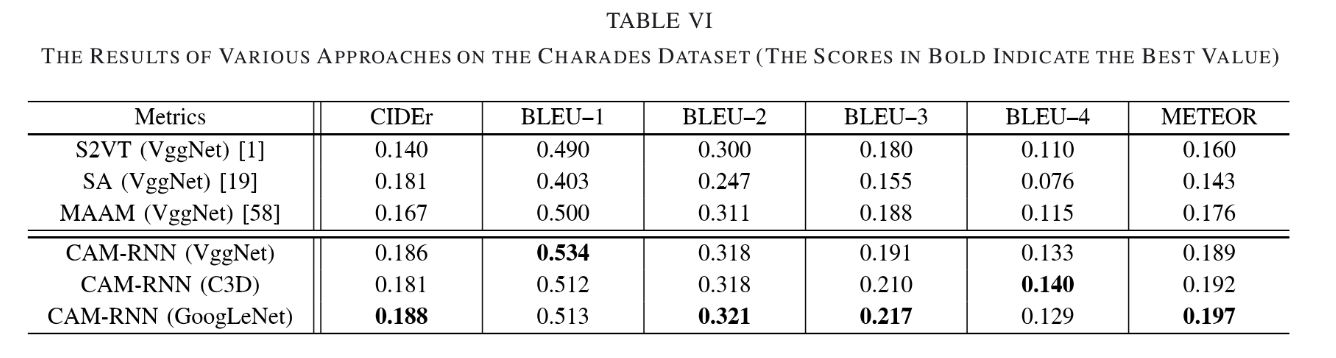
补充:【MAAM】是由记忆单元组成的attention模型,过去的attention记忆决定当前attention权重分布。相较于CAM-RNN同时对region层、frame层进行编码,MAAM只对frame层进行编码。
The MAAM is anattention model augmented by the memory unit, where theattention memory in the past time is utilized to determine thecurrent attention weight.
至于集中模型普遍在Charades上得分不高,是因为Charades是数据集中较有挑战性的一个数据集,其训练视频的参考描述均描述的是一连串的动作,作者也将四种模型分别对nonvisual words和visual words的错误率进行的测试比较:
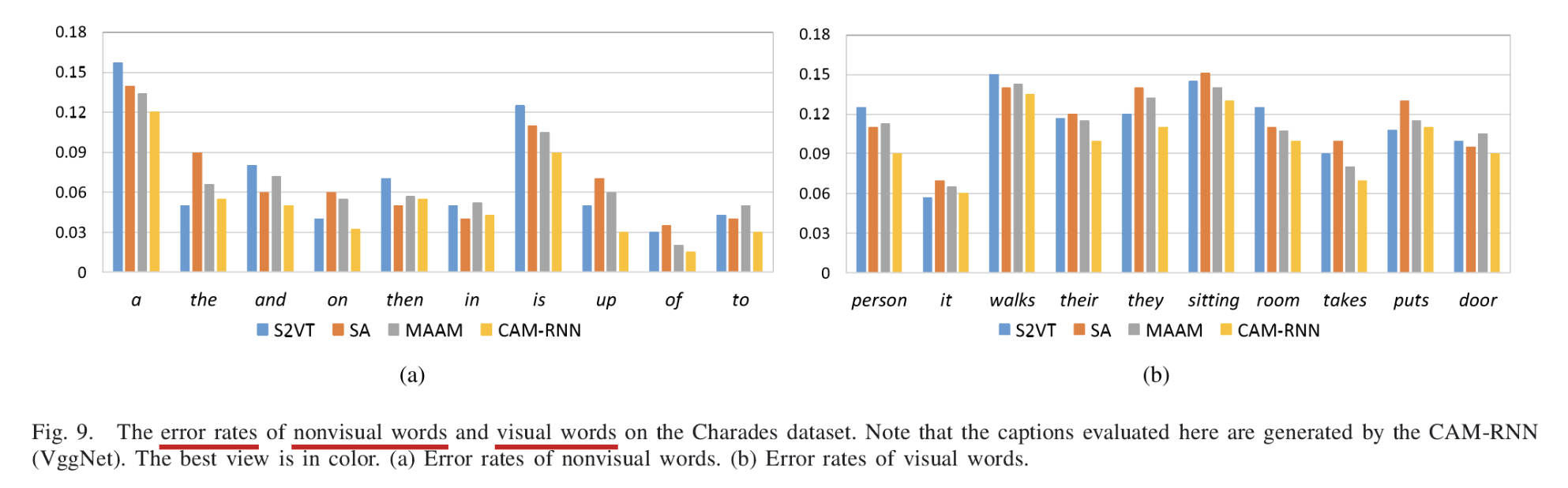
可以看出CAM-RNN在nonvisual words部分错误率普遍较低,而visual words部分错误率仍较高,由于部分描述主体物较小、或活动时间较短,难以捕捉获取其视觉特征。
4)Results on MSR-VTT
对于在MSVD上对比使用的模型和三个encoder,此处作者提到了视频的另一必要信息——音量信息(audio information),并将此也作为模型的特征输入,在MSR-VTT上的测试结果如下:
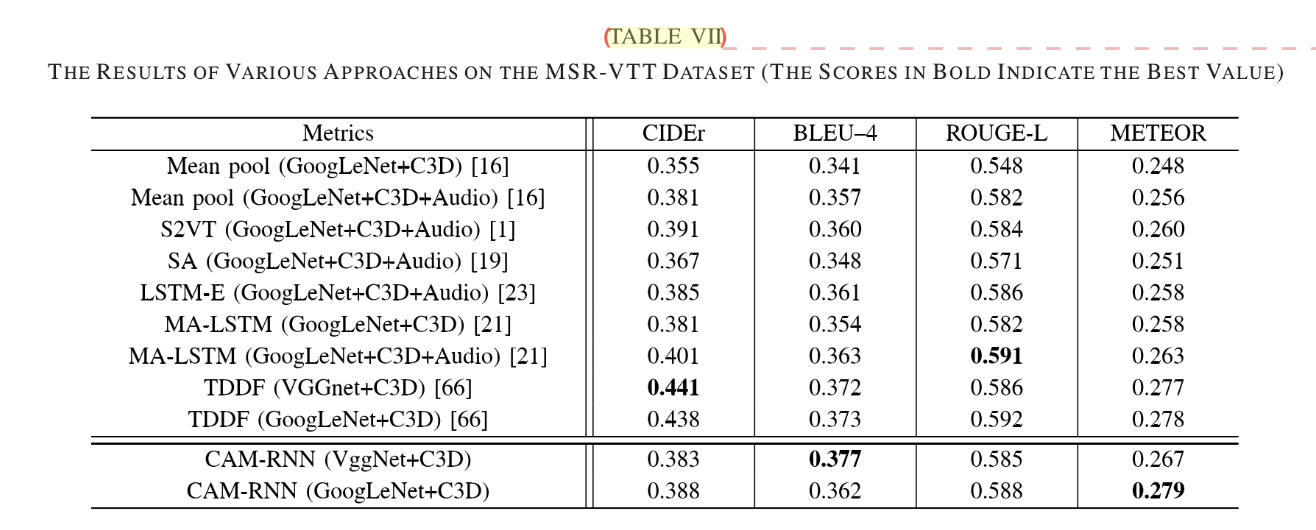
可见Audio信息对同配置的模型提升还是较为明显的,虽然我8知道音量信息是怎么嵌入的,感觉可以作为一个坑~
5)Results on MPII-MD
【对照组:Mean Pool、Visual-Lables、S2VT、S2VT-LM、LSTM-E、LSTM-TSA】在MPII-MD(METEOR)上的测试结果:
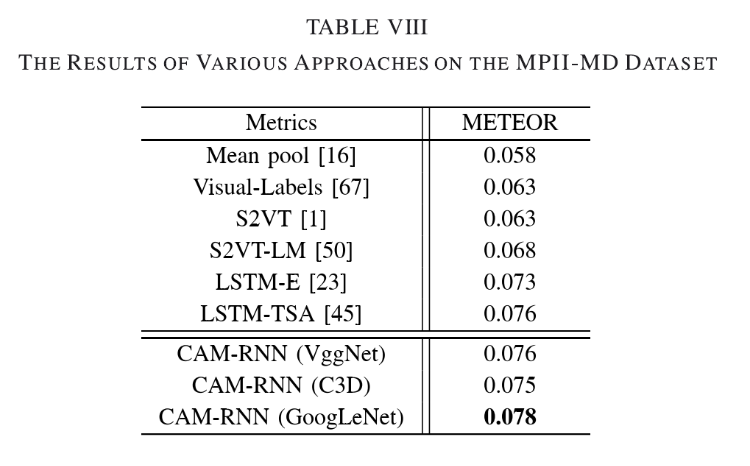
补充:
【Visual-Lables】CNN classifiers+LSTM, encoder部分是传统方法,LSTM是RNN方法,故也称Visual-Lables是传统方法和RNN方法的结合
【LSTM-TSA】结合了额外的视频信息生成描述_(?疑惑点)_
Talk
科研入门第一篇认认真真看完的paper,动机是因为2019-2020大创项目小组选择的作为框架的模型论文出处。说实话,在边写这篇summarize边回头复习这篇的时候,相比于之后陆陆续续看的CVPR等各种顶会的文章,真的觉得这是一篇除了平衡门没有什么特别创新的内容的论文,其CAM-RNN可以说是万金油的模型,故我个人更倾向于将其作为一种框架来使用,在将大创相关论文整理完成后我会写一篇我们模型的介绍博客以展示我对其”框架性“的理解。
但正是因为其内容、公式推导浅显易懂,模型框架与其他模型较容易进行比较,这篇论文帮助我养成了自己阅读论文的习惯、了解到了作者写论文所要做的工作及思路、也通过实验、相关工作的内容补上了很多课题上的知识漏洞——当然还有就是自己完完整整啃完一整篇论文时的自豪感。所以我将这篇作为自己的第一篇科研博客。之后我也会继续努力(・ิω・ิ)!

